
An Alternative Architecture for Real-Time Analytics

What is real-time analytics
Real-time analytics refers to the process of analyzing data as it is generated or received, enabling instant or near-instant insights and decision-making. It contrasts with traditional batch processing, where data is collected over a period of time and analyzed later. The core requirements of real-time analytics is access to fresh data and fast queries.
Key Aspects of Real-time Analytics :
Low latency Data ingestion : Data latency is a measure of the time from when data is generated to when it is queryable. There is usually a time lag between when the data is produced and when it is available to query. Real-time systems are designed to minimize that time lag.
Continuous Data Processing: Real-time analytics often deals with continuous streams of data from sources like IoT devices, transaction systems, or web applications.
Low Query Latency : Query latency is the time required to execute a query and return a result.
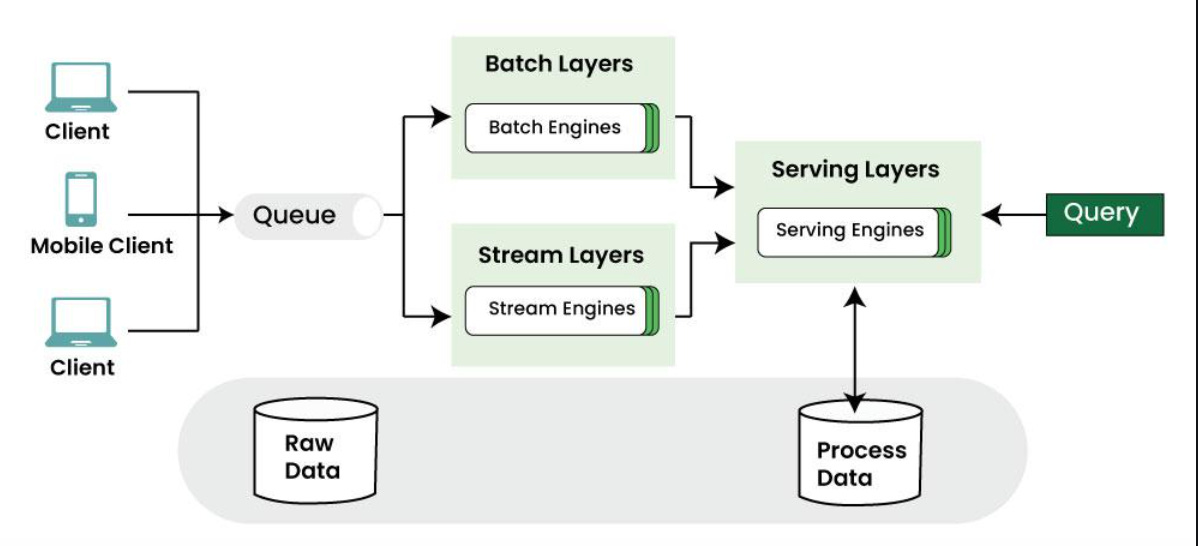
Traditional way of data processing is used batch to reprocess historical data and stream processing is used to process recent updates.The lambada architecture to combine the two.
The core idea of the lambada architecture is the stream processor consumes the event and quickly produces an approximate update to the view and the batch processor later consumes the same set of events and produce a corrected version of derived view.
Most processing in the Lambda architecture happens in the pipeline and not at query time. As most of the complex business logic is tied to the pipeline software, the application developer is unable to make quick changes to the application.
Aggregator/Leaf/Tailer pattern
The Aggregator/Leaf/Tailer pattern architecture addresses these shortcomings of Lambda architectures. The key component of Aggregator/Leaf/Tailer is a high-performance serving layer that serves complex queries, and not just key-value lookups. The existence of this serving layer obviates the need for complex data pipelines.
This approach allows us to separate the compute from durability and storage. The durability of non-indexed data is provided by Distributed log store (Kafka), and the storage for indexed data is provided by shared storage (S3).
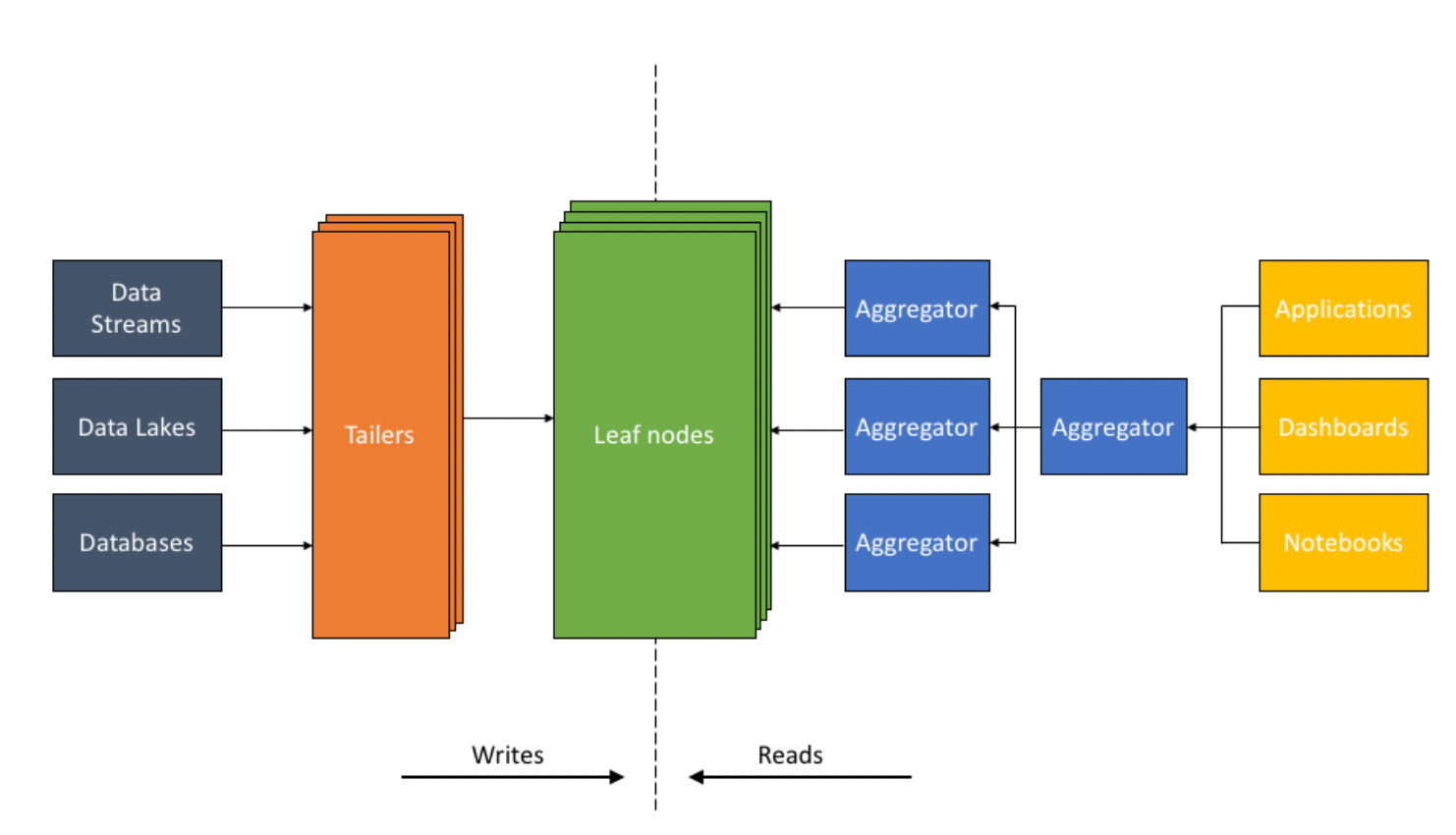
Tailer : The Tailer pulls new incoming data from a static or streaming source into an indexing engine. Its job is to fetch from all data sources.
Leaf: The Leaf is a powerful indexing engine. It indexes all data as and when it arrives via the Tailer.The goal of indexing is to make any query on any data field fast.
Aggregator: The Aggregator tier is designed to deliver low-latency aggregations, be it columnar aggregations, joins, relevance sorting, or grouping.
Comparison with Lambda architecture
For our discussion we will consider Apache Druid which is implementing Lambda architecture .
Separation of Ingest Compute and Query Compute
The Druid architecture employs nodes called data servers that are used for both ingestion and queries. In this design, high ingestion or query load can cause CPU and memory contention. For instance, a spike in ingestion workload can negatively impact query latencies.
In Aggregator Leaf Tailer architecture Tailers fetch new data from data sources, Leaves index and store the data and Aggregators execute queries in distributed fashion.Keeping compute resources separate between ingestion and queries, and allowing each to be scaled independently.The system can scales Tailers when there is more data to ingest and scales Aggregators when the number or complexity of queries increases. As a result, the system provides consistent query latencies even under periods of high ingestion loads.
Separation of Compute and Storage
Druid does not decouple compute and storage but combines them for performance reasons. Queries must be routed to the node on which the data resides and are limited by the compute resources on that node for execution. This means that query performance is closely tied to the fixed ratio of compute to storage on Druid nodes.
Aggregator Leaf Tailer architecture adds Leaves when there is more data to be managed and scales Aggregators when the query workload increases. Aggregator resources are not tied to where the data is located, so users can simply add compute as needed, without having to move to different hardware instances or change the distribution of data. The ability to share available compute across queries, regardless of where data is stored, also allows for more efficient utilization of resources.